하네스 엔지니어링: 지식 저장소의 4대 구성요소
문제상황
SSAFY 관통 프로젝트를 진행하다 이런 문제들이 있었다.
1️⃣ Spring AI가 아닌 HttpClient로 AI 기능을 구현해버림
- curl 요청 예시를 넘겨주니
HttpClient로 구현해버렸다. - 이후, 프롬프트에서 아티클 등록 시 파생 아티클 생성에 Spring AI 도입을 검토하라고 했었음
- 도입하고 나니, API 요청 날릴 때 빠진 필드가 있다며 작동하지 않음.
- 다시
HttpClient로 롤백... - 이후, Spring Boot 4 버전과 Spring AI 버전 간의 호환성 문제였던 것을 알게 됨
- Spring AI 버전을
2.0.0-M5로 올려서 컬렉션 구현 등등을 해결
- Spring AI 버전을
2️⃣ 레거시 코드가 남아있음

FE에서 디데이를 보여주려면, 백엔드에선 endAt 일자를 전달하고 디데이 계산은 FE가 하는 것이 낫다.
하지만 초반 mock 단계에서 잘못 만들어진 response 내 daysLeft라는 필드가 수 차례 수정 후에도 남아있는 것을 확인했다.
이는 수동으로 테스트하는 과정에서 발견하여 패치했으나, 이런 레거시 코드 클린업을 알잘딱으로 하게 할 수 없나? 라는 생각이 들었다. 그리고 한편으로는, 일부러 남겨놓아야 하는 레거시도 있을텐데?? 라는 생각도 들었다.
AGENTS.md의 한계
처음에는 프로젝트 컨벤션, 가이드라인 등�을 AGENTS.md 파일에 다 넣었다.
하지만 프로젝트 볼륨이 점점 늘어나면서, 이러한 방식은 다음의 문제가 있었다.
- 문맥 상실: 파일이 커지고 규칙이 누적될수록, 에이전트가 간간히 규칙을 안 지키는 현상이 발생했다.
- 토큰 소모 증가: 간단한 수정에도 전체 규칙 파일을 매번 컨텍스트에 밀어넣으면서 비용이 증가했다.
- 상충되는 규칙: 아티클은
HttpClient이고 컬렉션은 Spring AI라서, 코덱스가 아티클과 컬렉션 간 구현 방식 차이에 혼란을 겪고 있다.- 🤷♀️ 왜 아티클을
HttpClient로 냅둠?: 토큰 아껴야 돼서요. 아직 기능 구현이 우선임
- 🤷♀️ 왜 아티클을
지식 저장소
단일 AGENTS.md의 한계를 극복하기 위해, OpenAI Codex 팀을 비롯한 현대 에이전트 아키텍처는 구조화된 지식 저장소 패러다임을 사용한다.
지식 저장소는 모든 규칙을 한곳에 몰아넣는 것이 아니라, 성격에 따라 문서를 split 하고 에이전트의 작업 context에 따라 필요한 문서만 적시(Just-in-Time)에 주입하는 방식이다.
이를 통해 에이전트의 메타 인지를 높이고, 토큰 낭비를 막을 수 있다.
지식 저장소의 4대 구성요소
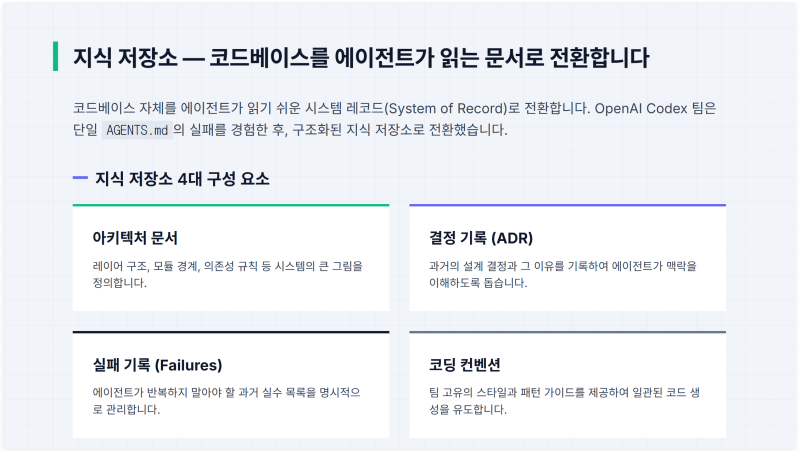
1. 아키텍처 문서
- 시스템의 큰 그림, 레이어 구조, 모듈 간의 의존성 규칙을 정의
- "현재 백엔드는 Spring Boot 4 기반이며, 외부 라이브러리 도입 시 호환성을 최우선으로 검증해야 함" 같은 대원칙을 명시한다. 이를 통해 에이전트가 무작정
HttpClient로 롤백하는 대신, 프레임워크 생태계 내에서 호환되는 버전(ex.2.0.0-M5)을 먼저 탐색하도록 유도할 수 있다.
2. 결정 기록 (ADR: Architecture Decision Record)
- 과거의 기술적 설계 결정과 그 이유를 기록
- 일부러 남겨놓아야 하는 레거시 에 대한 답이 될 수 있다. 예를 들어,
0015-keep-article-generation-using-httpclient.md라는 문서를 만들고 "토큰 절약을 위해 레벨별 파생 아티클 생성 시 Spring AI가 아닌 HttpClient 기반 API 호출 방식은 당분간 유지함"이라고 기록해 두면, 에이전트가 마음대로 이 코드를 건드리거나 혼동을 겪지 않는다. (한편, 이러한 기록이 없다면 과감히 클린업하거나 리팩토링하도록 제어할 수도 있다.)
3. 실패 기록
- 에이전트가 반복하지 말아야 할 과거의 실수, 버그, 트러블슈팅 내역
- Spring AI 버전 호환성 이슈 를 기록할 수 있다.
"문제: Spring AI 도입 시 API 필드 누락 에러 발생. 원인: Spring Boot 4와의 버전 불일치. 해결책: 반드시 버전을 2.0.0-M5 이상으로 명시할 것."
4. 코딩 컨벤션
- 팀 내 코드 스타일, 데이터 흐름 패턴, API 디자인 가이드
- 디데이 계산 규칙 을 여기에 정의한다.
"D-Day 데이터는 BE에선 기준 일자만 전달하며, 계산은 FE가 전담한다."라는 컨벤션을 명시해 두면, 에이전트가 API를 만들 때 처음부터daysLeft같은 필드를 만드는 실수를 원천 차단할 수 있다.
지식 저장소 생성하기
- 프로젝트 루트에
.agent/또는.context/폴더를 생성한다. - 하네스 초기화 프롬프트를 작성하고 실행한다.
### 역할
당신은 Harness Engineering System을 구축하는 시니어 아키텍트입니다.
agent/dev-note 경로의 report 문서들을 분석하여, 에이전트가 앞으로 작업을 수행할 때 참고할 수 있는 지식 저장소 문서를 구조화하여 생성하세요.
모든 문서는 프로젝트 루트의 `.context/` 디렉토리 하위에 마크다운 파일로 생성되어야 하며, 다음 4대 구성 요소를 반드시 포함해야 합니다.
---
### 지식 저장소 4대 구성 요소 생성 가이드
1. 아키텍처 문서 (`.context/architecture.md`)
- 목적: 시스템의 레이어 구조, 모듈 간의 경계, 기술 스택 및 버전 대원칙 정의
- 포함 내용: 현재 사용 중인 핵심 프레임워크(ex. Spring Boot 4 등)와 의존성 규칙, 패키지 구조 가이드를 명시
2. 결정 기록 (`.context/adr/` 폴더 내 개별 문서)
- 목적: 과거의 기술적 설계 결정과 그 맥락을 기록하여 '의도된 레거시나 특이 구조'를 보존
- 포함 내용: 최근 아키텍처 변경점이나 특정 설계 패턴을 선택한 이유를 ADR(Architecture Decision Record) 형식으로 작성 (ex. "FE 구버전과의 호환성을 위해 특정 구형 필드나 API 구조를 유지함" 등)
3. 실패 기록 (`.context/failures.md`)
- 목적: 에이전트가 반복하지 말아야 할 과거의 실수, 버전 충돌, 버그 트러블슈팅 내역 관리
- 포함 내용: 최근 발생했던 치명적인 에러나 삽질 기록을 명시적으로 기록 (ex. "Spring AI 도입 시 특정 버전 이하에서 API 필드 누락으로 인한 HttpClient 롤백 이슈 -> 해결을 위해 Spring AI 버전을 2.0.0-M5 이상으로 고정해야 함" 등)
4. 코딩 컨벤션 (`.context/styleguide.md`)
- 목적: 팀 고유의 코드 스타일, 데이터 처리 흐름 패턴, API 디자인 가이드 제공
- 포함 내용: Linter 규칙 외에도 우리 프로젝트만의 데이터 흐름 규칙을 정의 (ex. D-Day 같은 연산 데이터는 백엔드에서 계산하여 주지 않고 기준 일자만 전달하며, 계산은 프론트엔드가 전담한다" 등)
---
### 수행 규칙
- 추상적이고 뻔한 문장이 아니라, 현재 코드베이스의 실제 파일명, 프레임워크 버전, 비즈니스 로직에 기반한 구체적인 컨텍스트를 녹여내어 문서를 작성할 것
- 없는 사실을 지어내지 말고, 확실하지 않은 아키텍처 결정이나 실패 기록은 template만 잡아두고 주석으로 추후 채워 넣을 수 있도록 가이드할 것
분석을 완료했다면 `.context/` 폴더와 하위 파일들을 생성하고, 어떤 구조로 지식 저장소를 빌드했는지 요약해줘

이전에 계속 report로 작업 내역을 기록해놔서 문서 생성은 그리 어렵지 않았다.
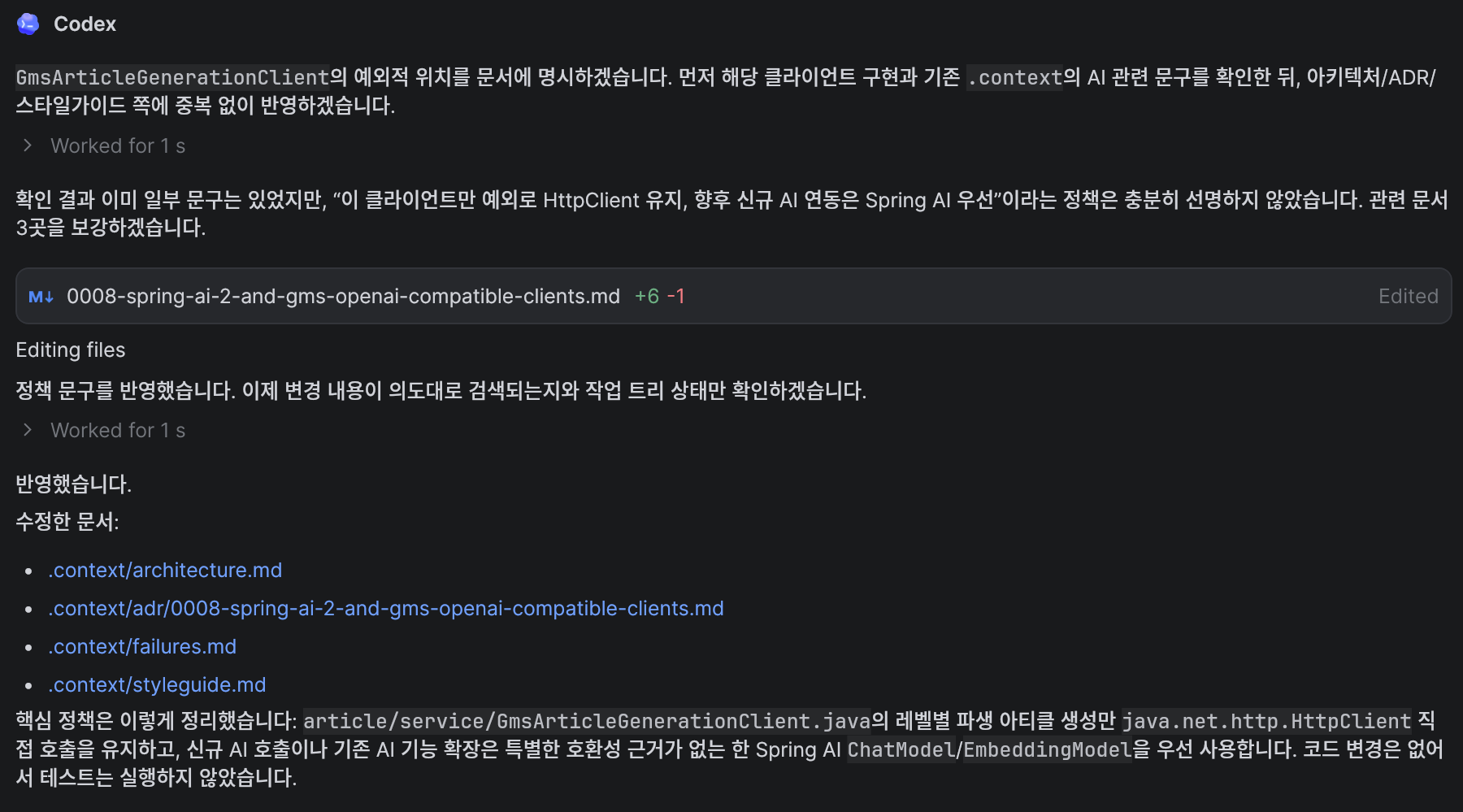
다만 HttpClient 관련은 명시적으로 나온 내용이 없는 것 같아 따로 추가했다.
article 도메인에선 아티클 등록 시 레벨별 파생 아티클 생성 과정에서 Spring AI가 아닌 HttpClient 로 API 요청을 처리하고 있는데, 이 부분만 HttpClient 방식을 유지하고, 앞으로는 계속 Spring AI 방식을 사용한다는 점을 지식 저장소에 반영해
AGENTS.md로 지식 저장소 적용하기
그동안 계속 프롬프트에 수동으로 넣어서 요청했던 작업 내역 report 작성 과 API 명세서 작업 도 포함했다.
가장 대중적인 방법을 요청했지만, 사실상 아직은 AGENTS.md 방식밖에 없다.
앞으로 새 세션으로 에이전트 작업을 할 때, 매번 프롬프트에 작성하지 않아도 자동으로 기본적으로 하단의 수행을 하게끔 만들고 싶어
1. `.context/architecture.md`를 읽고 시스템 아키텍처 규칙을 위배하지 않는지 확인할 것
2. `.context/adr/` 폴더 내의 문서들을 확인하여, 수정하려는 코드에 보존해야 하는 레거시 맥락이 있는지 검증할 것
3. `.context/failures.md`를 읽고, 작업 중인 부분과 관련된 과거 실패 사례를 체크하여 같은 실수를 방지할 것
4. 작업 완료 후 새로운 트러블슈팅이나 아키텍처 결정이 발생했다면, 관련된 지식 저장소 문서(.md)를 스스로 업데이트할 것
5. 코딩 작업은 agent/dev-note 에 현재 브랜치 번호(ex. feature/{브랜치 번호})를 포함한 파일명으로 작업 내역을 기록한 report 문서를 작성하고, 필요시 agent/docs 경로의 API 명세서도 업데이트할 것
가장 대중적인 방식으로 요구사항을 해결해줘

AGENTS.md에 보안 거버넌스를 반영하지 않은 이유
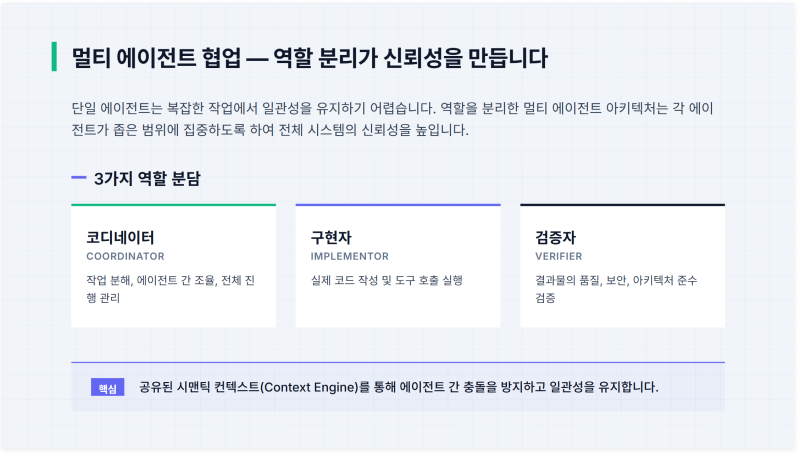
지난 하네스 엔지니어링으로 Codex env 유출 막기 스터디 문서를 작성하며 생각해보았는데, 보안 거버넌스는 개인적으로 현재의 에이전트 컨텍스트가 아닌 완전 분리된 SAST tool과 별도의 검증 에이전트에서 관리해야 한다는 입장이다.
단일 에이전트 구조에서, 컨텍스트에 '시크릿 넣지마' 라고 하면, 문서에 '시크릿은 넣지 않았습니다' 라고 계속 작성해두는 문제가 있었는데, 이는 멀티 에이전트 구조로 설계해서 완전 분리된 verifier 에이전트가 시크릿 검사 역할만 수행하게끔 만들면 해결되는 문제라 그렇다.
궁극적으로 내 지갑 상황이 문제인듯